This user guide can be used as a walkthrough for reading and processing tracking data files with the Workflow.R script. You can use the example datasets provided in Data, or try with your own tracking data (see Pre-flight checks for details on data requirements and structure).
The following diagram gives an overview of the workflow (boxes link to relevant section):
%%{init:{'flowchart':{'nodeSpacing': 20, 'rankSpacing': 30}}}%%
flowchart LR
S1[Read in data] ==> S3(Merge)
S2[Read in metadata] ==> S3 ==> A(Clean)
subgraph shiny ["(Parameter determination in Shiny app)"]
style shiny fill:#fbfbfb, stroke:#d3d3d3, stroke-width:px
A(Clean) ==> B(Process) ==> C(Filter)
D(Optional<br/>scripts)
end
C ==> S{Standardised<br/>dataset}
C --> D --> S
S --> E(Analyses)
S ==> F(Archive)
linkStyle 6,7 stroke-dasharray: 4 4
%% NOTE: remember to update links for finalised user guide!!
click S1 "#read-in-data-files";
click S2 "#merge-with-metadata";
click S3 "#merge-with-metadata";
click A "#cleaning";
click B "#processing";
click C "#filtering";
click S "#save-data";
%% click ? "#summarise-data";
%% click ? "#visualisation";
Figure 1: Diagram of workflow used for analysing movement data (thick line denotes core path of code)
Use our example data sets in the Data folder (RFB_IMM, RFB, GWFG, TRPE) or provide your own data
User inputs
Some code chunks require editing by the user to match the specific dataset being used (particularly if you are using your own data), and are highlighted as below (the 🧠 indicates you will need to think about the structure and format of your data when making these edits!):
🧠 User input required
#--------------------### USER INPUT START ###--------------------#example_input<-"uservalue"# In the R code, user input sections appear like this#------------------### USER INPUT END ###------------------#
0. Pre-flight checks
How to use this workflow:
We will inspect the data before reading it in, so there is no need to open it in another program (e.g., excel, which can corrupt dates and times)
User-defined parameters (see user inputs) are called within the subsequent processing steps
Where you see: ## ** Option ** ##, there is an alternative version of the code to fit some common alternative data formats
Throughout, we will use some key functions to inspect the data (e.g., head for top rows, str for column types, and names for column names)
Data and directory structure:
Data files should all be stored within the Data folder
Folders and files are best named in snakecase_format as spaces in filepaths can cause issues
Tracking data for each deployment/individual should be in a separate file
Tracking data filenames should include an ID which is the same length for all individuals
Tracking data must contain a timestamp and at least one other sensor column
Metadata file should be in the parent directory of data files
Metadata should contain one row per individual per deployment NB: if you have multiple animal movement projects, these should have completely separate directories
The importance of ID:
Throughout this workflow, we use ID to refer to the unique code for an individual animal
In certain cases, you might have additional ID columns in the metadata (e.g., DeployID),
or read in data with a unique TagID instead of ID.
This code will work as long as all of the relevant info is included in the metadata
For more info and helpful code, see the FAQ document & troubleshooting script
How to troubleshoot problems if something doesn’t work with your data:
Refer to the FAQ document in the GitHub page, which signposts to helpful resources online (e.g., CRS)
See the troubleshooting code scripts that we’ve written to accompany this workflow (e.g., using multiple ID columns for re-deployments of tags/individuals)
All functions in code chunks are automatically hyperlinked to their documentation, so feel free to explore this if you want to understand more about how this code works!
Load required libraries
Just before starting we load in all the packages we will need for the workflow (also referenced in the Dependencies section).
Throughout the script, we’ll be saving files using a species code as a file/folder identifier. Our code is taken from the first letters of the species name (Red Footed Booby) but can be anything you choose (shorter the better as long as it’s unique per species). Let’s define this object first for consistency:
species_code<-"RFB"
Set filepath for the folder containing raw data files (this code will try to list and open all files matching the file pattern within this folder, so it is best if this folder contains only the raw data files). NB:if you are working outside of a project, you’ll need to check that here is using the correct working directory.
filepath<-here("Data", species_code)#create relative filepath using folder name and species code
Define common file pattern to look for. An asterisk (*) is the wildcard, will match any character except a forward-slash (e.g. *.csv will import all files that end with “.csv”).
filepattern<-"*.csv"# data file format
Let’s view the file names, to check that we have the files we want & find ID position (this list will include names of sub-folders).
Adjust these numbers for extracting the ID number from file name using stringr (e.g. to extract GV37501 from “GV37501_201606_DG_RFB.csv”, we want characters 1-7). NB:this approach only works if all ID’s are the same length and in the same position — see the str_sub documentation for other options.
IDstart<-1#start position of the ID in the filename IDend<-7#end position of the ID in the filename
Now, let’s inspect the data by reading in the top of the first data file as raw text. To inspect the first row of all data files (if you wanted to check column names), you can remove the [1] and change n_max = 1).
test<-fs::dir_ls(path =filepath, recurse =TRUE, type ="file", glob =filepattern)[1]read_lines(test, n_max =5)# change n_max to change the number of rows to read in
Define number of lines at top of file to skip (e.g. if importing a text file with additional info at top).
skiplines<-0
Define date format(s) used (for passing to lubridate) (d = day as decimal, m = month as decimal, y = year without century, Y = year with century). Parsing will work the same for different date delimiters (e.g. “dmY” will work for both 01-12-2022 and 01/12/2022). lubridate can even parse more than one date/time format within a dataframe, so if your data include multiple formats, make sure they are all included. Here, we’ve included some common combinations — modify if your data include a different format
date_formats<-c("dmY", "Ymd")#specify date formats datetime_formats<-c("dmY HMS", "Ymd HMS")#specify date & time format
Define time zone for tracking data.
trackingdatatimezone<-"GMT"
By default, the below code will find column names from the first row of data. If you want to specify your own column names, do so here as a character vector, or use set colnames <- FALSE to automatically number columns.
colnames<-TRUE
Here, we use the function read_delim and specify the delimiter to make this code more universal (you can find extra information on this in the readr documentation).
Some delimiter examples:
"," = comma delimited (equivalent to using read_csv – saved as extension .csv)
"\t" = tab delimited (equivalent to using read_tsv — saved as extension .tsv)
" " = whitespace delimited (equivalent to using read_table)
Let’s inspect the data again, this time skipping rows if set, to check the file delimiter.
user_delim<-","user_trim_ws<-TRUE# Should leading/trailing whitespaces be trimmed
Finally, data need an ID column, either be the tag ID (“TagID”) or individual ID (“ID”). Specify ID type here, for later matching with the same column in the metadata:
With the user inputs specified in the previous section, we’ll now read in and merge all tracking data files directly from the github repository, extracting the ID from the filename of each file.
df_combined<-fs::dir_ls(path =filepath, # use our defined filepath glob =filepattern, # use file pattern type ="file", # only list files recurse =TRUE# look inside sub-folders)%>%purrr::set_names(nm =basename(.))%>%# remove path prefixpurrr::map_dfr(read_delim, # use read_delim function .id ="filename", # use filename as ID column col_types =cols(.default ="c"), # as character by default col_names =colnames, # use colnames object made above skip =skiplines, # how many lines to skip delim =user_delim, # define delimiter trim_ws =user_trim_ws)%>%# trim characters or notmutate("{ID_type}":=str_sub(string =filename, # extract ID from filename start =IDstart, end =IDend), # ID position .after =filename)# move the new ID column after filename columndf_combined
If your data are combined into one or multiple csv files containing an ID column, use the following approach instead (this is the same code, but doesn’t create a new ID column from the file name):
# ** Option **df_combined<-fs::dir_ls(path =filepath, #use filepath glob =filepattern, # use file pattern type ="file", # only list files recurse =TRUE# look inside sub-folders)%>%purrr::map_dfr(read_delim, # use read_delim function col_types =cols(.default ="c"), # as character by default col_names =colnames, # use colnames object made above skip =skiplines, # how many lines to skip delim =user_delim, # define delimiter trim_ws =user_trim_ws)# trim characters or notdf_combined
First, data need a time stamp, either in separate columns (e.g., “Date” and “Time”) or combined (“DateTime”). Below we specify which column’s date and time info are stored in the data. NB:These have to be in the same order as specified in earlier user input, i.e. “Date” and “Time” have to be the right way round
datetime_colnames<-c("Date", "Time")# or c("DateTime")
You can also have additional columns depending on the type of logger used, for example:
## lc = Argos fix quality## Lat2/Lon2 = additional location fixes from Argos tag## laterr/lonerr = location error information provided by some GLS processing packages
Here we’re going to slim down the dataset by selecting the necessary columns & coercing some column names. You should change column names below to those present in your tracking data, additional columns can be added (see above examples). This process standardises important column names for the rest of the workflow (e.g., TagID, Lat, Lon)
df_slim<-data.frame(ID =as.character(df_combined$ID), Date =df_combined$Date, Time =df_combined$Time, Y =df_combined$Latitude, X =df_combined$Longitude)
🧠 User input required
Here’s an example of how to change the above code for data with different columns and column names. This code works with immersion data recorded by a GLS logger (no location data)
df_slim<-data.frame(ID =df_combined$ID, Date =df_combined$`DD/MM/YYYY`, Time =df_combined$`HH:MM:SS`, Immersion =df_combined$`wets0-20`)
Parse dates, create datetime, date and year columns
Now our df_slim is ready, we need to create a DateTime column. Using the datetime_colnames object we made previously, we’ll combine columns (if needed), and then parse a single DateTime column using the lubridate package:
df_slim<-df_slim%>%tidyr::unite(col ="DateTime_unparsed", # united column nameall_of(datetime_colnames), # which columns to unite sep =" ", # separator between values in new column remove =FALSE# remove original columns?)%>%mutate(DateTime =lubridate::parse_date_time(DateTime_unparsed, # parse DateTime orders =datetime_formats, # formats tz =trackingdatatimezone), # timezone Date =lubridate::as_date(DateTime), Year =lubridate::year(DateTime))%>%select(-DateTime_unparsed)
Warning: There was 1 warning in `mutate()`.
ℹ In argument: `DateTime = lubridate::parse_date_time(...)`.
Caused by warning:
! 1 failed to parse.
Note
n failed to parse warnings means a date or time was not in the correct format for lubridate to create a date_time object, producing NAs. We can look at the failing rows using the following code:
ID Date Time Y X DateTime Year
1 GV37501 <NA> 5.06 -7.261829 72.376091 <NA> NA
Now we can see the issue: Date is empty, and Time is saved as a number. We’ll remove this row in the @cleaning section, so don’t need to do anything else for the moment.
Lastly, we make a df_raw dataframe by sorting using ID and DateTime, dropping NA’s in DateTime column
Metadata are an essential piece of information for any tracking study, as they contain important information about each data file, such as tag ID, animal ID, or deployment information, that we can add back into to our raw data when needed. For example, the table below shows what the first few columns of the metadata file looks like for our example red-footed booby data:
Then much like in Step 1, we define the date format(s) used (for passing to lubridate) (d = day as decimal, m = month as decimal, y = year without century - 2 digits, Y = year with century - 4 digits). Here, we’ve included common combinations, which you’ll need to modify if your metadata include a different format (run OlsonNames() to return a full list of time zones names).
metadate_formats<-c("dmY", "Ymd")#specify date format used in metadatametadatetime_formats<-c("dmY HMS", "Ymd HMS")#specify date & time formatmetadatatimezone<-"Indian/Chagos"#specify timezone used for metadata
Next we read in the metadata file (make sure to check the read_ function you’re using matches your data format!).
df_metadata<-readr::read_csv(filepath_meta)# Read in metadata filenames(df_metadata)
Select metadata columns
🧠 User input required
Then we select necessary columns & create a new complete dataframe, making sure to provide four compulsory columns: ID — as defined in tracking data (individual ID or TagID), deployment date & deployment time. We can also provide optional columns depending on sensor type: e.g. colony, sex, age. You can add or delete other columns where appropriate.
If you have multiple ID columns like TagID/DeployID, include them here (for example, if one individual was tracked over multiple deployments/years, or if one tag was re-deployed on multiple individuals). For more information and helpful code, see the FAQ document and troubleshooting script.
Deployment and retrieval dates: Different tags types sometimes require specific approaches for dealing with data collected outside of deployment period (e.g., before deployment or after retrieval). If data need to be filtered for one or both of these scenarios, we need to sort out these columns in the metadata, and if not relevant for the data, set the column name to “NA”.
Central Place foragers: If you are working with a central place forager (e.g., animals returning to a breeding location) and you have individual breeding location information in your metadata, here is a good place to add this info to the tracking data (e.g., breeding seabirds with known individual nest location, or seals returning to known haul-out location). We recommend adding these columns as: CPY = Central place Y coordinate column & CPX = Central place X coordinate column
df_metadataslim<-data.frame(ID =as.character(df_metadata$BirdID), # compulsory column TagID =as.character(df_metadata$TagID), DeployID =as.character(df_metadata$DeployID), DeployDate_local =df_metadata$DeploymentDate, # compulsory column (make NA if irrelevant) DeployTime_local =df_metadata$DeploymentTime, # compulsory column (make NA if irrelevant) RetrieveDate_local =df_metadata$RetrievalDate, # compulsory column (make NA if irrelevant) RetrieveTime_local =df_metadata$RetrievalTime, # compulsory column (make NA if irrelevant) CPY =df_metadata$NestLat, CPX =df_metadata$NestLong, Species ="RFB", Population =df_metadata$Population, Age =df_metadata$Age, BreedStage =df_metadata$BreedingStage)
Option: select alternative columns
For the example dataset RFB_IMM (immature red-footed boobies), we can use the following:
df_metadataslim<-data.frame(ID =as.character(df_metadata$bird_id), # compulsory column TagID =as.character(df_metadata$Tag_ID), DeployID =as.character(df_metadata$Deploy_ID), DeployDate_local =df_metadata$capture_date, # compulsory column (set to NA if irrelevant) DeployTime_local =df_metadata$capture_time, # compulsory column (set to NA if irrelevant) RetrieveDate_local =NA, # compulsory column (set to NA if irrelevant) RetrieveTime_local =NA, # compulsory column (set to NA if irrelevant) DeployY =df_metadata$lat, DeployX =df_metadata$long, Species ="RFB", Age =df_metadata$age)
Format all dates and times, combine them and specify timezone (NA’s in deployment/retrieval date times will throw warnings, but these are safe to ignore if you know there are NA’s in these columns).
df_metadataslim<-df_metadataslim%>%mutate(Deploydatetime =lubridate::parse_date_time(paste(DeployDate_local, DeployTime_local),# make deploy datetime order =metadatetime_formats, tz =metadatatimezone), Retrievedatetime =lubridate::parse_date_time(paste(RetrieveDate_local, RetrieveTime_local), # make retrieve datetime order=metadatetime_formats, tz=metadatatimezone))%>%select(-any_of(c("DeployDate_local", "DeployTime_local", "RetrieveDate_local", "RetrieveTime_local")))%>%mutate(across(contains('datetime'), # for chosen datetime column~with_tz(., tzone =trackingdatatimezone))#format to different tz)
Here we’ll create a dataframe of temporal extents of our data to use in absence of deploy/retrieve times (this is also useful for basic data checks and for writing up methods).
Now we pipe the data through a series of functions to drop NAs in specified columns, filter out user-defined no_data_values in LatLon columns, remove duplicates, remove undeployed locations and filter out locations within temporal cut-off following deployment.
df_clean<-df_metamerged%>%drop_na(all_of(na_cols))%>%filter(!X%in%No_data_vals&!Y%in%No_data_vals)%>%# remove bad Lat/Lon valuesdistinct(DateTime, ID, .keep_all =TRUE)%>%# NB: might be an issue for ACC without msfilter(case_when(!is.na(Retrievedatetime)# for all valid datetimes~Deploydatetime<DateTime&# keep if datetime after deployment...DateTime<Retrievedatetime, # ...and before retrieval .default =Deploydatetime<DateTime))# filter deployment only if retrieve date is NA (i.e., sat tags) head(df_clean)
Argos fix quality can be used to filter the data set to remove locations with too much uncertainty. If you know the error classes that you want to retain in a dataset, you can run this filter below. NB:If you want to do further exploration of location quality (e.g., from GPS PTT tags to compare locations with contemporaneous GPS locations), keep all location classes by skipping this step.
In this example we define a vector of location classes to keep (typically, location classes 1, 2, and 3 are of sufficient certainty), and filter out everything else.
lc_keep<-c("1", "2", "3")df_clean<-df_clean%>%filter(lc%in%lc_keep)# filter data to retain only the best lc classes
Finally we remove intermediate files/objects:
rm(list=ls()[!ls()%in%c("df_clean", "species_code")])#specify objects to keep
4. Processing
Perform some useful temporal and spatial calculations on the data
🧠 User input required
First we need to specify the co-ordinate projection systems for the tracking data and meta data. The default here is lon/lat for both tracking data & metadata, for which the EPSG code is 4326. For more information see the CRS section of the FAQ’s or have a look at the ESPG.io database.
tracking_crs<-4326# Only change if data are in a different coordinate systemmeta_crs<-4326# Only change if data are in a different coordinate system
Next we transform coordinates of data, and perform spatial calculations. This requires spatial analysis, and so it is good practice to run all spatial analyses in a coordinate reference system that uses metres as a unit.
The default CRS for this workflow is the Spherical Mercator projection — (crs = 3857), which is used by Google Maps/OpenStreetMap and works worldwide. However, this CRS can over-estimate distance calculations in some cases, so it’s important to consider the location and scale of your data (e.g., equatorial/polar/local scale/global scale) and choose a projection system to match. Other options include (but are not limited to) UTM, and Lambert Azimuthal Equal-Area (LAEA) projections.
transform_crs<-3857
Here we’ll calculate some useful movement metrics from the tracking data, including distance between fixes, time between fixes, and net displacement from the first fix.
df_diagnostic<-df_clean%>%ungroup()%>%#need to ungroup to extract geometry of the whole datasetmutate(geometry_GPS =st_transform(# transform X/Y coordinatesst_as_sf(., coords=c("X","Y"), crs =tracking_crs), #from original format crs =transform_crs)$geometry# to the new transform_crs format)%>%group_by(ID)%>%#back to grouping by ID for calculations per individualmutate(dist =st_distance(geometry_GPS, # distance travelled from previous fix, lag(geometry_GPS), by_element =T), # calculations are done by row difftime =difftime(DateTime, lag(DateTime), # time passed since previous fix units ="secs"), # in seconds netdisp =st_distance(geometry_GPS, # dist. between 1st and current locationgeometry_GPS[1], by_element =F)[,1], # dense matrix w/ pairwise distances speed =as.numeric(dist)/as.numeric(difftime), # calculate speed (distance/time) dX =as.numeric(X)-lag(as.numeric(X)), #diff. in lon relative to prev. location dY =as.numeric(Y)-lag(as.numeric(Y)), #diff. in lat relative to prev. location turnangle =atan2(dX, dY)*180/pi+(dX<0)*360)%>%# angle from prev. to current locationungroup()%>%select(-c(geometry_GPS, dX, dY))# ungroup and remove excess geometries
Add latitude and longitude column — this can be useful for plotting and is a common coordinate system used in the shiny app
Here we’re going to save df_diagnostic to use in the Shiny app provided. The app is designed to explore how further filtering and processing steps affect the data.
🧠 User input required
First, we use here to create a file path for saving the working dataframe files, and create the folder if missing
filepath_dfout<-here("DataOutputs","WorkingDataFrames")# create filepathdir.create(filepath_dfout)# create folder if it doesn't exist
Next we define file name for the saved file by pasting the species code before _diagnostic (can change this if you want to use a different naming system).
Remove everything except df_diagnostic ahead of the next step.
rm(list=ls()[!ls()%in%c("df_diagnostic", "species_code")])#specify objects to keep
6. Filtering
This second filtering stage is designed to remove outliers in the data, and you can use outputs from the Shiny app to inform these choices. If you don’t need to filter for outliers, skip this step and keep using df_diagnostic in the next steps.
Upload your csv version of df_diagnostic to the app by clicking the Upload data button in the top left.
At the bottom of each app page are printed code chunks that can be copied into subsequent user input section. These code chunks contain the user input values you manually select in the app
Define threshold values
For this section, you can either use the code chunks produced by the Shiny app, or manually define the threshold values yourself. If you’re using the Shiny app, you can copy the code chunks from the bottom of each page to replace the user input section below. If you’re manually defining the threshold values, you can edit each of the variables below as you would for any of the user input sections (we have suggested some for the RFB dataset).
🧠 User input required
First we define a period to filter after tag deployment, when all points before the cutoff will be removed (e.g. to remove potentially unnatural behaviour following the tagging event). We define this period using the as.period function, by providing an integer value and time unit (e.g. hours/days/years). This code below specifies a period of 30 minutes:
Then we define speed threshold in m/s, which we will use to remove any points with faster speeds.
filter_speed<-20
Next we define a net displacement (distance from first point) threshold and specify units. Any points further away from the first tracking point will be removed (see commented code for how to retain all points):
filter_netdisp_dist<-300filter_netdist_units<-"km"# e.g., "m", "km"#If you want to retain points no matter the net displacement value, use these values instead:#filter_netdisp_dist <- max(df_diagnostic$netdisp)#filter_netdist_units <- "m"
Implement filters
Create net displacement filter using distance and units
df_filtered<-df_diagnostic%>%filter(Deploydatetime+filter_cutoff<DateTime, # keep times after cutoffspeed<filter_speed, # keep speeds slower than speed filternetdisp<=filter_netdisp)# keep distances less than net displacement filterhead(df_filtered)
rm(list=ls()[!ls()%in%c("df_filtered", "species_code")])#specify objects to keep
7. Summarise cleaned & filtered tracking data
🧠 User input required
Set the units to display sampling rate in the summary table
sampleRateUnits<-"mins"
Define levels of grouping factors to summarise over
Firstly, down to population level. Here, we are working on data from one population & year, and so use Species as the grouping factor. Add any other relevant grouping factors here (e.g. Country / Year / Season / Age).
Create a summary table of individual-level summary statistics:
df_summary_ind<-df_filtered%>%group_by(across(c(all_of(grouping_factors_poplevel), all_of(grouping_factors_indlevel))))%>%summarise(NoPoints =NROW(ID), # number of fixes NoUniqueDates =length(unique(Date)), # number of tracking dates FirstDate =as.Date(min(Date)), # first tracking date LastDate =as.Date(max(Date)), # last tracking date SampleRate =mean(as.numeric(difftime, units =sampleRateUnits), na.rm =T), # sample rate mean SampleRate_se =se(as.numeric(difftime, units =sampleRateUnits)))# sample rate standard error
`summarise()` has grouped output by 'Species'. You can override using the
`.groups` argument.
Create a table of population-level summary statistics:
df_summary_pop<-df_summary_ind%>%# use the individual-level summary datagroup_by(across(grouping_factors_poplevel))%>%summarise(NoInds =length(unique(ID)), # number of unique individuals NoPoints_total =sum(NoPoints), # total number of tracking locations FirstDate =as.Date(min(FirstDate)), # first tracking date LastDate =as.Date(max(LastDate)), # last tracking date PointsPerBird =mean(NoPoints), # number of locations per individual: mean PointsPerBird_se =se(NoPoints), # number of locations per individual: standard error DatesPerBird =mean(NoUniqueDates), # number of tracking days per bird: mean DatesPerBird_se =se(NoUniqueDates), # number of tracking days per bird: standard error SampleRate_mean =mean(SampleRate), # sample rate mean SampleRate_se =se(SampleRate))# sample rate standard errordf_summary_pop
Here we define file names for saved files, and paste the species code to _summary_, followed by ind (individual level) or pop (population level). You can change this if you want to use a different naming system.
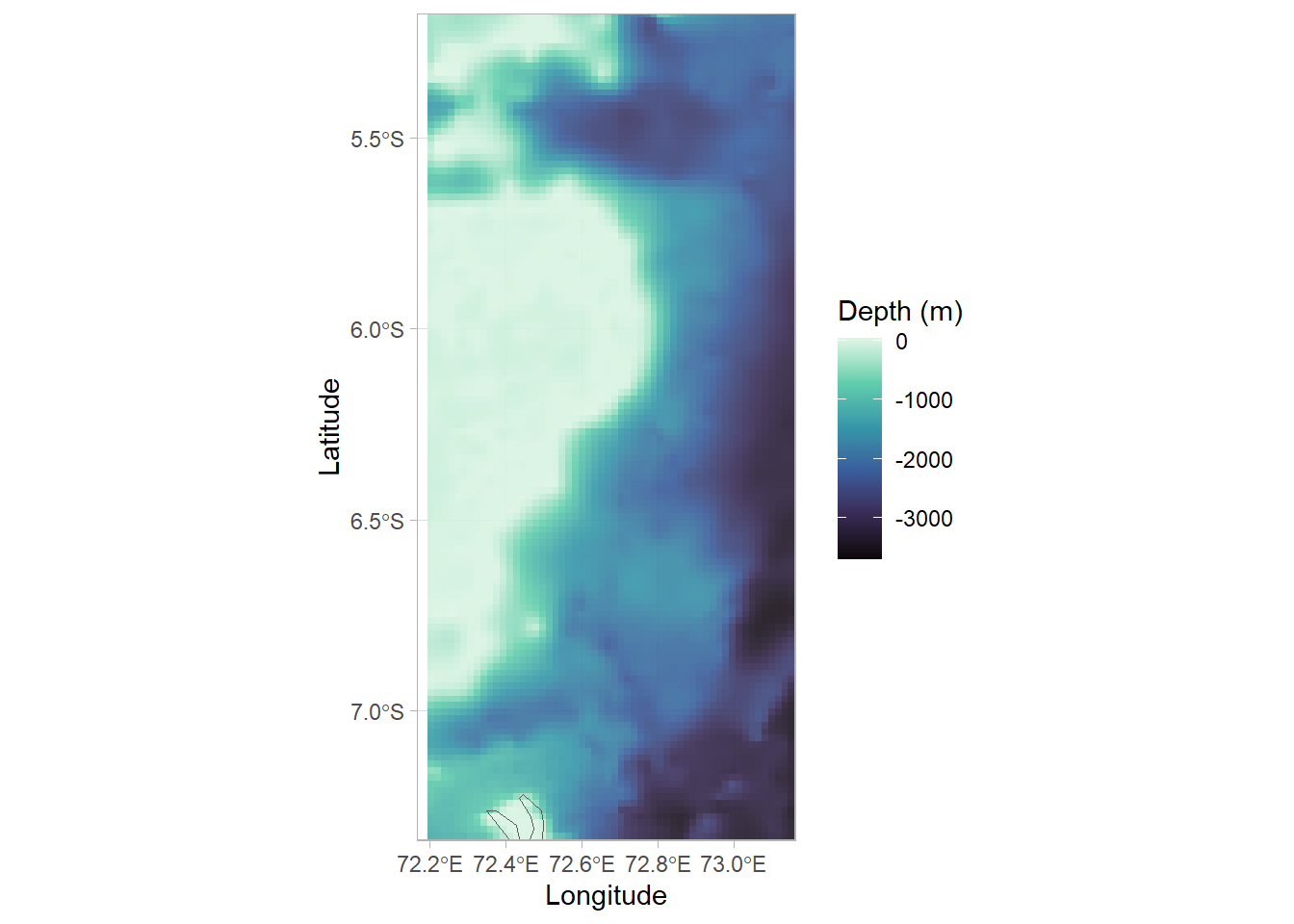
We plot maps over a topography base-layer which can include terrestrial (elevation) and marine (bathymetry/water depth) data. To set legend label for topography data, relevant to your data.
topo_label="Depth (m)"
Load additional libraries for spatial visualisation (optional)
If you see a masking warning these are fine. Watch out for packages that aren’t installed yet
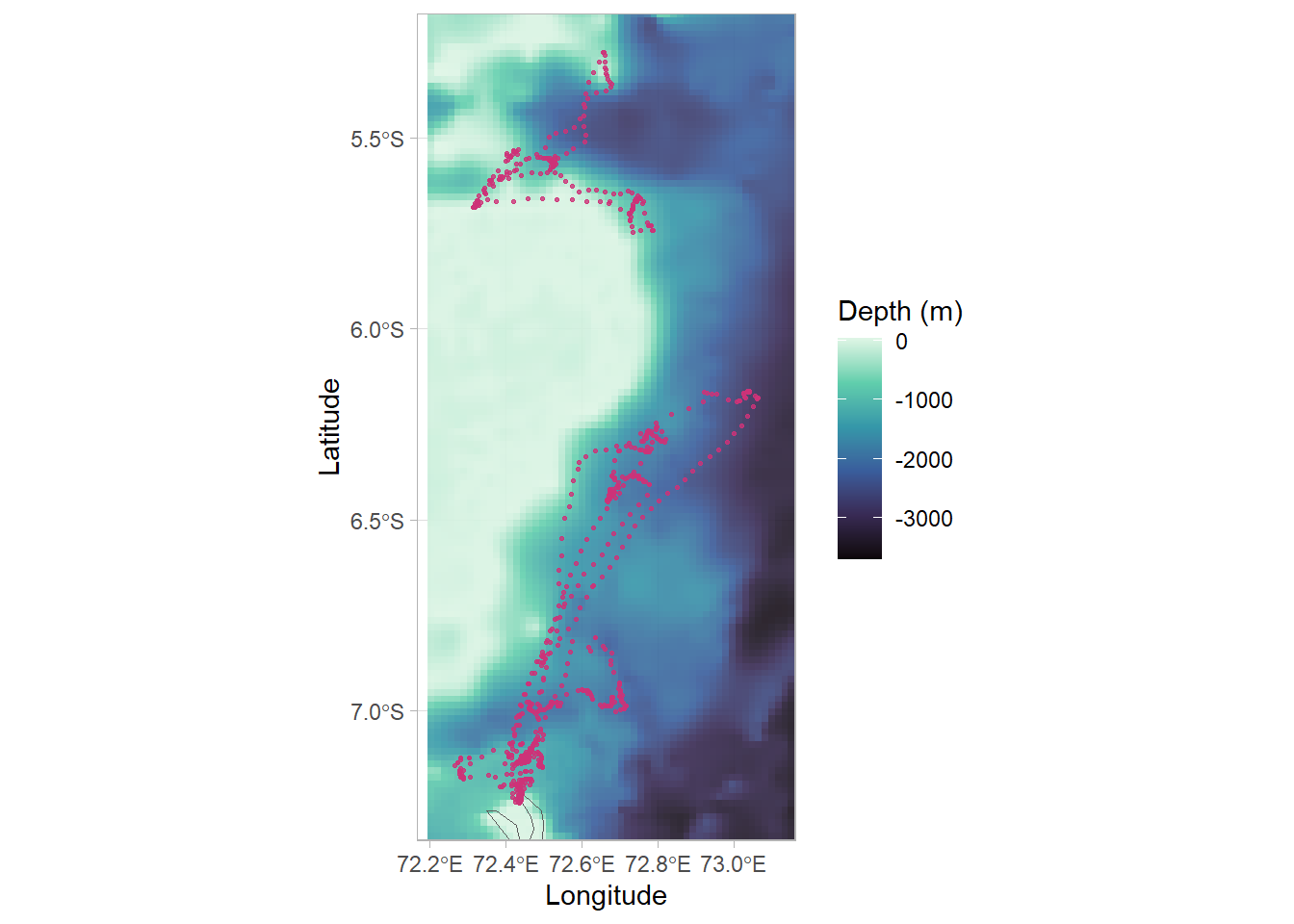
map_alllocs<-map_base+# add GPS pointsgeom_point(data =df_plotting, aes(x =Lon, y =Lat), alpha =0.8, size =0.5, col ="violetred3")map_alllocs
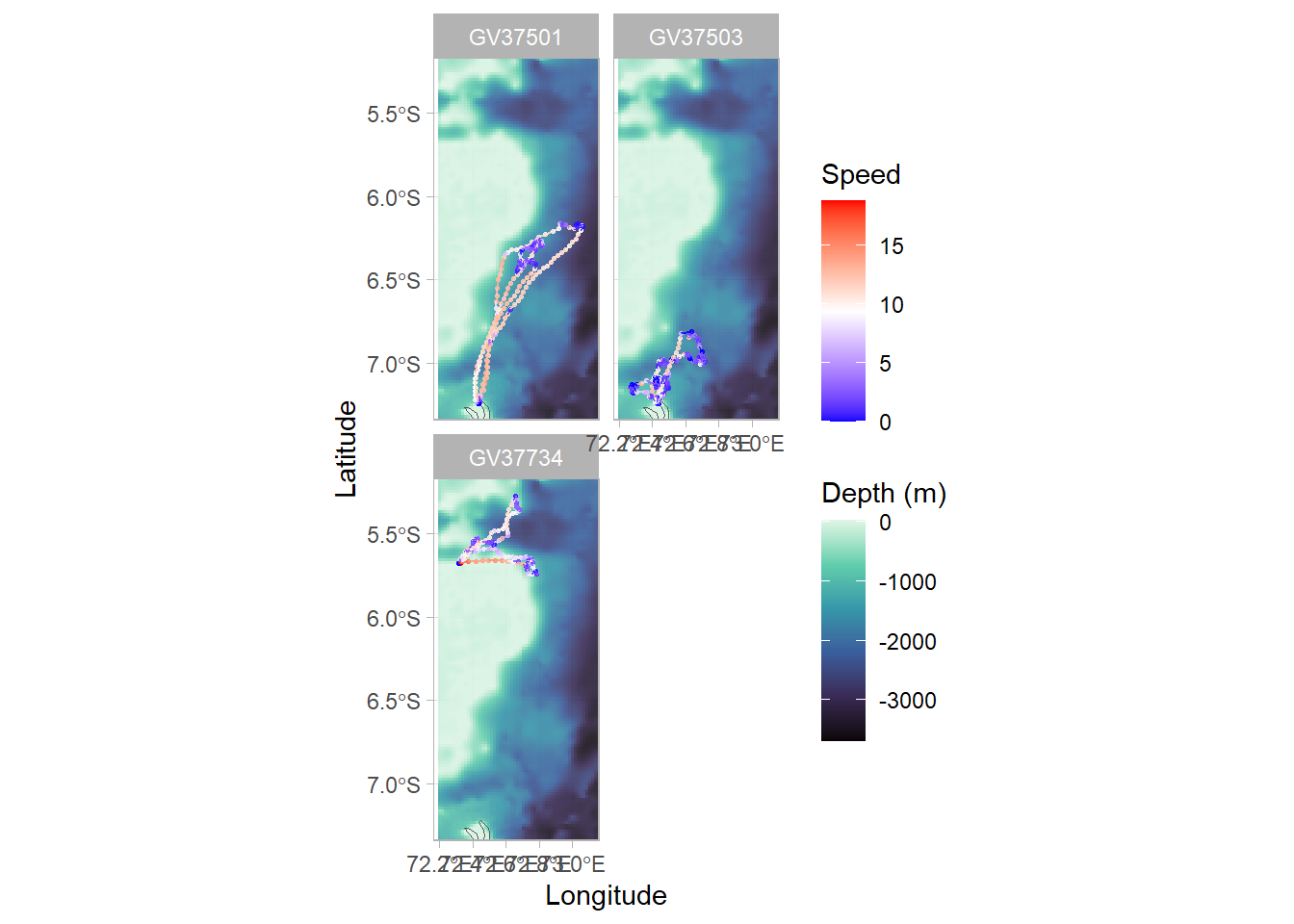
Plot a map of individual locations, colouring points by speed, and faceting by ID
map_individuals<-map_base+# add GPS points and paths between themgeom_point(data =df_plotting, aes(x =Lon, y =Lat, col =speed), alpha =0.8, size =0.5)+geom_path(data =df_plotting, aes(x =Lon, y =Lat, col =speed), alpha =0.8, size =0.5)+# colour birds using scale_colour_gradient2scale_colour_gradient2(name ="Speed", low ="blue", mid ="white", high ="red", midpoint =(max(df_plotting$speed,na.rm=TRUE)/2)# use `midpoint` for nice colour transition)+facet_wrap(~ID, # facet for individual ncol =round(sqrt(n_distinct(df_plotting$ID))))
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
map_individuals
In previous plots, we’ve split the population into individual facets. This works fine on the example code, where we only have a few individuals, but if you have more individuals and the facets are too small, you can split the plot onto multiple pages. Use the below code to use facet_wrap_paginate from the ggforce package:
## ** Option ** #### save plot as object to later extract number of pages## e.g., with 2 per page:map_individuals<-map_base+geom_point(data =df_plotting, # add GPS pointsaes(x =Lon, y =Lat, col =speed), alpha =0.8, size =0.5)+geom_path(data =df_plotting, #and paths between themaes(x =Lon, y =Lat, col =speed), alpha =0.8, size =0.5)+scale_colour_gradient2(name ="Speed", # colour speed w/ scale_colour_gradient2 low ="blue", mid ="white", high ="red", midpoint =(max(df_plotting$speed,na.rm=TRUE)/2))+facet_wrap_paginate(~ID, # facet for individual ncol =2, nrow=1, page =1)
How many pages of plots?
n_pages(map_individuals)
Run through different values of page to show each page in turn
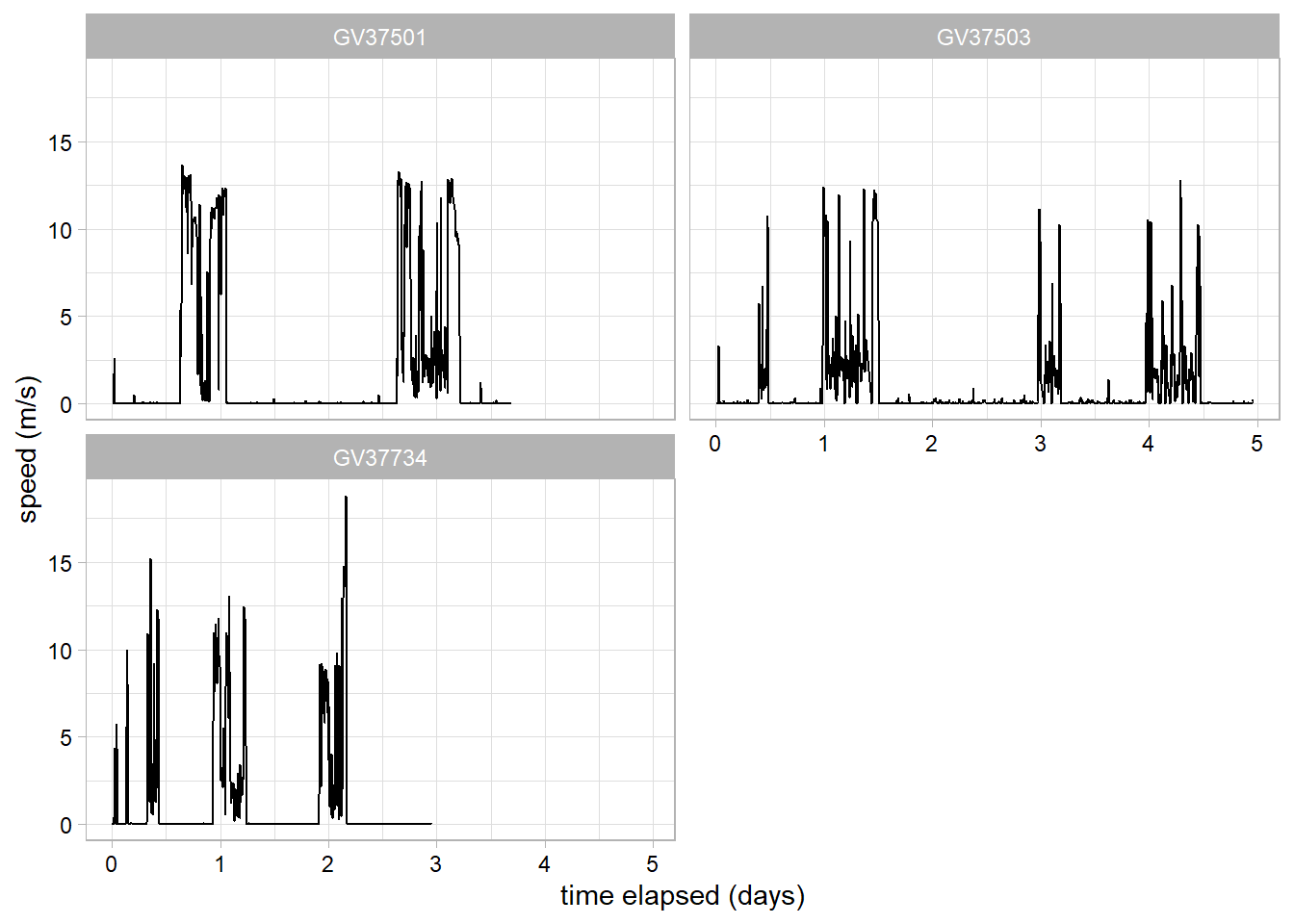
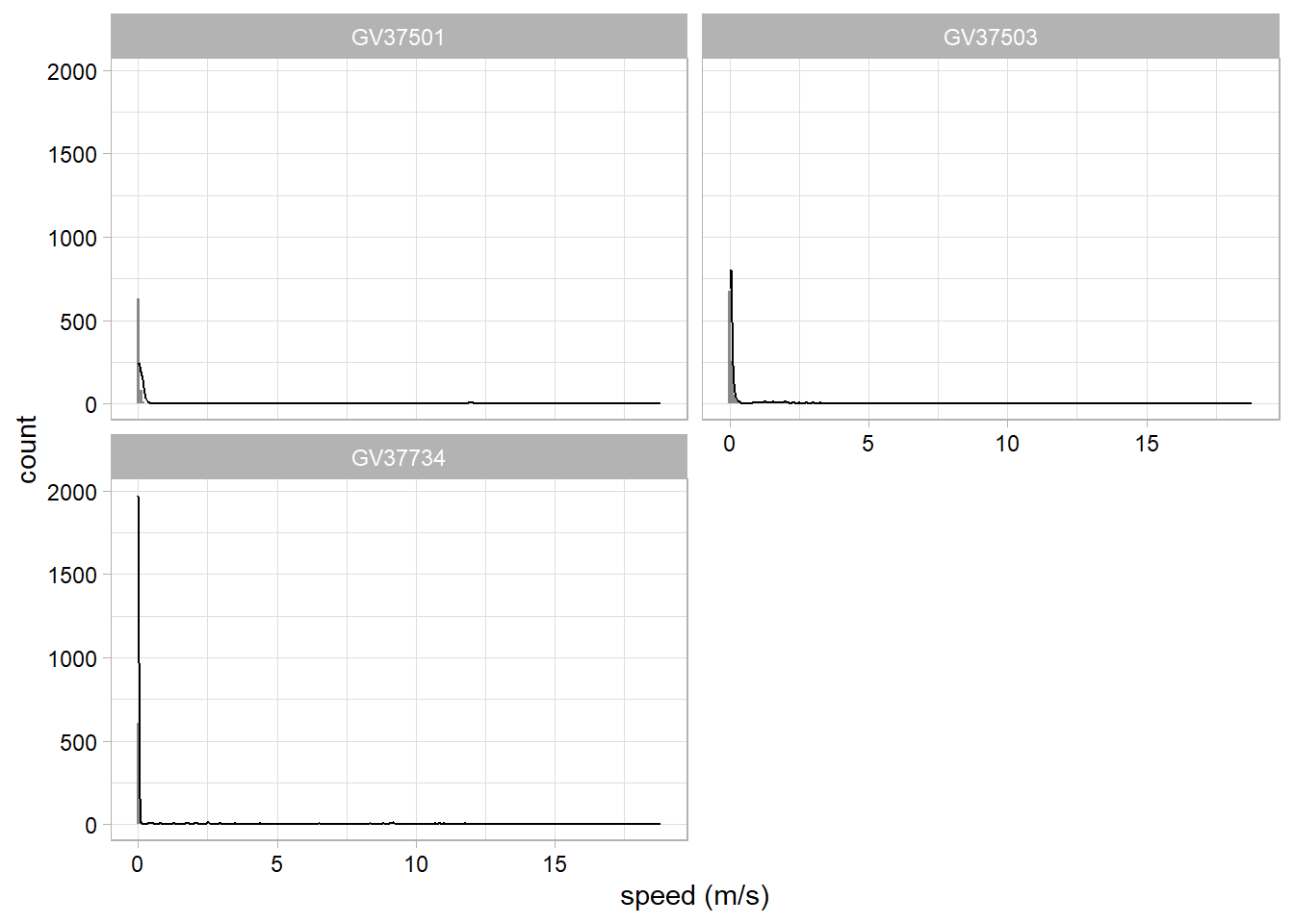
Create a time series plot of speed, faceted for each individual.
speed_time_plot<-df_plotting%>%#speed over timeggplot(data =., aes(x =days_elapsed, y =speed, group =ID))+geom_line()+# add line of speed over timexlab("time elapsed (days)")+ylab("speed (m/s)")+facet_wrap(~ID, # facet by individual nrow =round(sqrt(n_distinct(df_plotting$ID))))+theme_light()+# set plotting themetheme(axis.text =element_text(colour="black"))#adjust themespeed_time_plot
Note
Warnings about non-finite values for speed/step length plots are expected and usually refer to the first location for each individual (i.e. number of non-finite values should be equal to number of individuals)
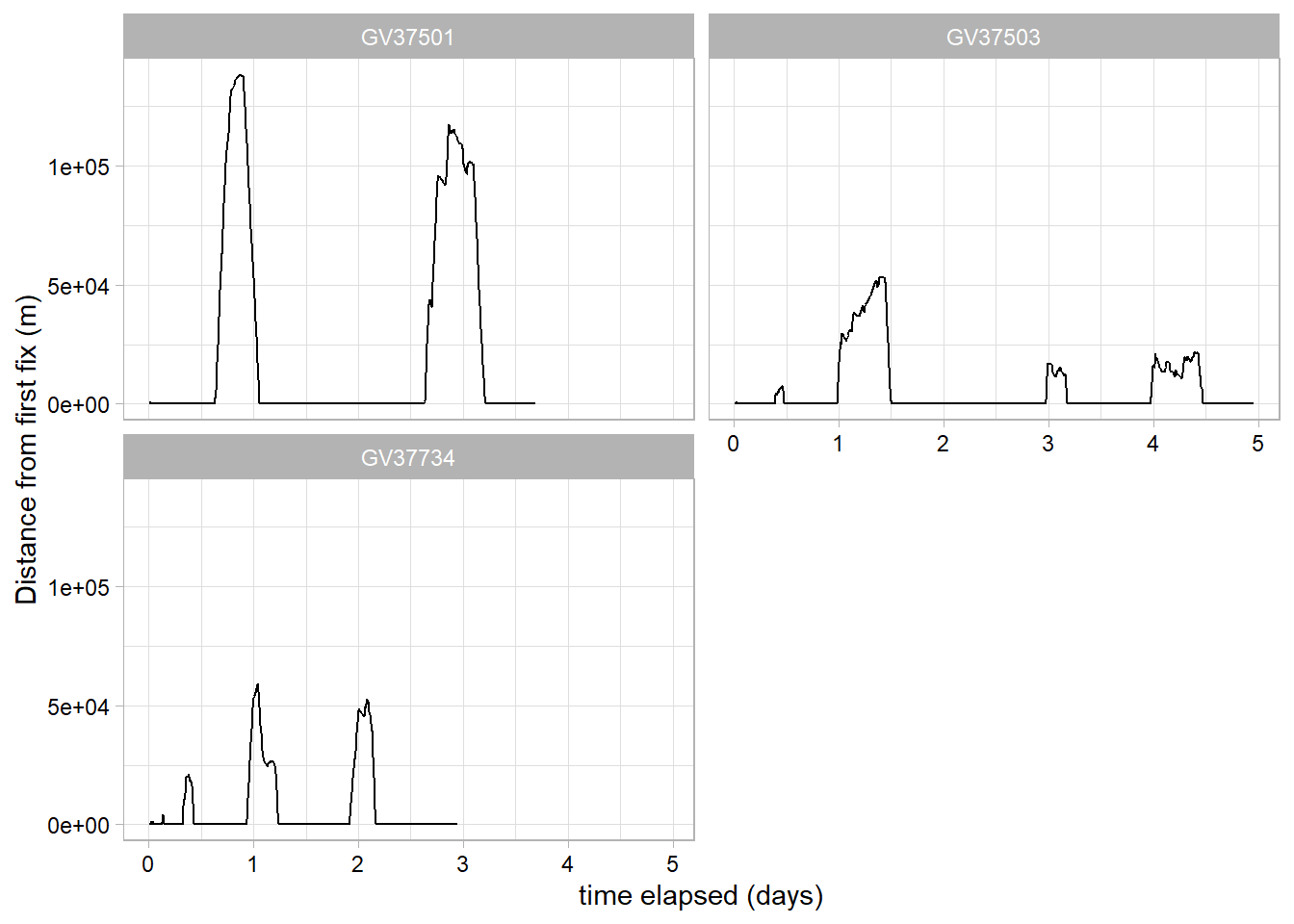
Create a time series plot of step lengths (faceted for each individual)
step_time_plot<-df_plotting%>%#step length over timeggplot(data =., aes(x =days_elapsed, y =as.numeric(netdisp), group =ID))+geom_line()+# add plot labelsxlab("time elapsed (days)")+ylab("Distance from first fix (m)")+facet_wrap(~ID, # facet by individual nrow=round(sqrt(n_distinct(df_plotting$ID))))+theme_light()+# set plotting themetheme(axis.text =element_text(colour="black"))#adjust themestep_time_plot